
はじめまして、エンジニアのshoheiです。
最近、ローカルLLMを自分のPCで動かしてみたのですが、想像以上に導入が簡単だったのでその内容を共有します。
ローカルLLMは「完全無料」で「機密情報を気にせず使える」のが魅力ですが、「構築が難しそう」と敬遠されがちです。しかし、「LM Studio」というツールを使えば、専門知識がなくても驚くほど簡単に環境が整います。
今回は、LM Studioの利便性と、実際にPythonで「採用窓口のAIコンシェルジュ」を作ってみた体験をご紹介します。
前提
ローカルLLMとは?
ローカルLLMとは、ChatGPTのようにインターネット経由で利用するのではなく、自分のPC(ローカル環境)にAIモデルをダウンロードして動かす仕組みのことです。
主な特徴としては、以下の点が挙げられます。
- プライバシー・セキュリティ: 入力したデータが外部のサーバーに送信されないため、機密情報を扱うことができます。
- コスト: 自分のPCのスペックを利用するため、月額費用やAPIの従量課金が発生せず、無料で使い放題です。
- オフライン利用: 一度モデルをダウンロードしてしまえば、インターネット環境がなくても動作します。
LM Studioとは?
LM Studioは、Windows、Mac、Linuxで利用できるデスクトップアプリケーションです。 何がすごいかというと、モデルの検索・ダウンロードから、ローカルでのAPIサーバーの立ち上げまで、すべて直感的なGUI(画面操作)で完結するところです。
使いたいモデル(Llama 3やQwenなど)を検索窓で探し、Downloadボタンを押すだけ。そして「Local Server」タブからサーバーを起動すれば、あっという間に自分のPCがAIサーバーに早変わりします。
わずか3ステップ!LM Studioの導入・設定手順
実際にPythonから呼び出す前に、LM StudioをインストールしてAPIサーバーを立ち上げておきましょう。手順は非常に簡単です。
ステップ1:ダウンロードとインストール
LMStudioの公式サイトにアクセスし、お使いのOS(Mac, Windows, Linux)に合ったインストーラーをダウンロードしてインストールします。特別な設定は不要で、一般的なアプリと同じようにインストールできます。 Macを使用しているので今回はMac版をインストールしてます。
ステップ2:使いたいモデルをダウンロード
LM Studioを起動したら、左側のメニューアイコンから「Model Search」(一番下)をクリックします。
次に上部の検索窓(Searchバー)で使いたいモデルを検索します。 例えば、日本語に強い軽量モデルなら Qwen や Llama-3-8B-Instruct などで検索してみてください。 一覧から良さそうなモデル(ファイルサイズや量子化レベルが自分のPCのメモリに合うもの)を選び、「Download」ボタンを押します。
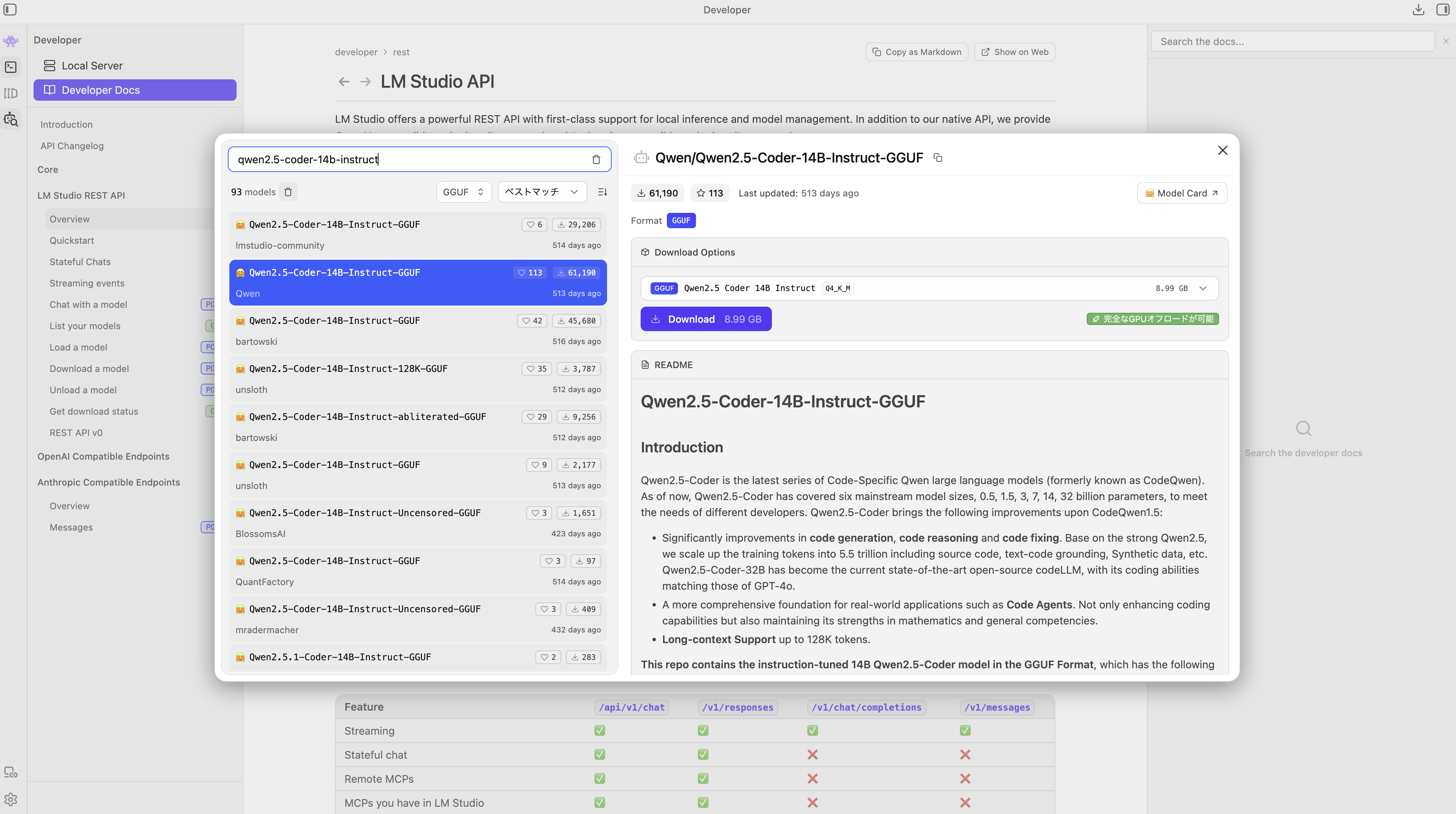
ステップ3:ローカルサーバー(APIサーバー)を起動
ダウンロードが完了したら、左側のメニューアイコンから「Developer」(上から2番目)をクリックします。
- 画面上部の「Load Model」ボタンから、先ほどダウンロードしたモデルを選択して読み込みます。
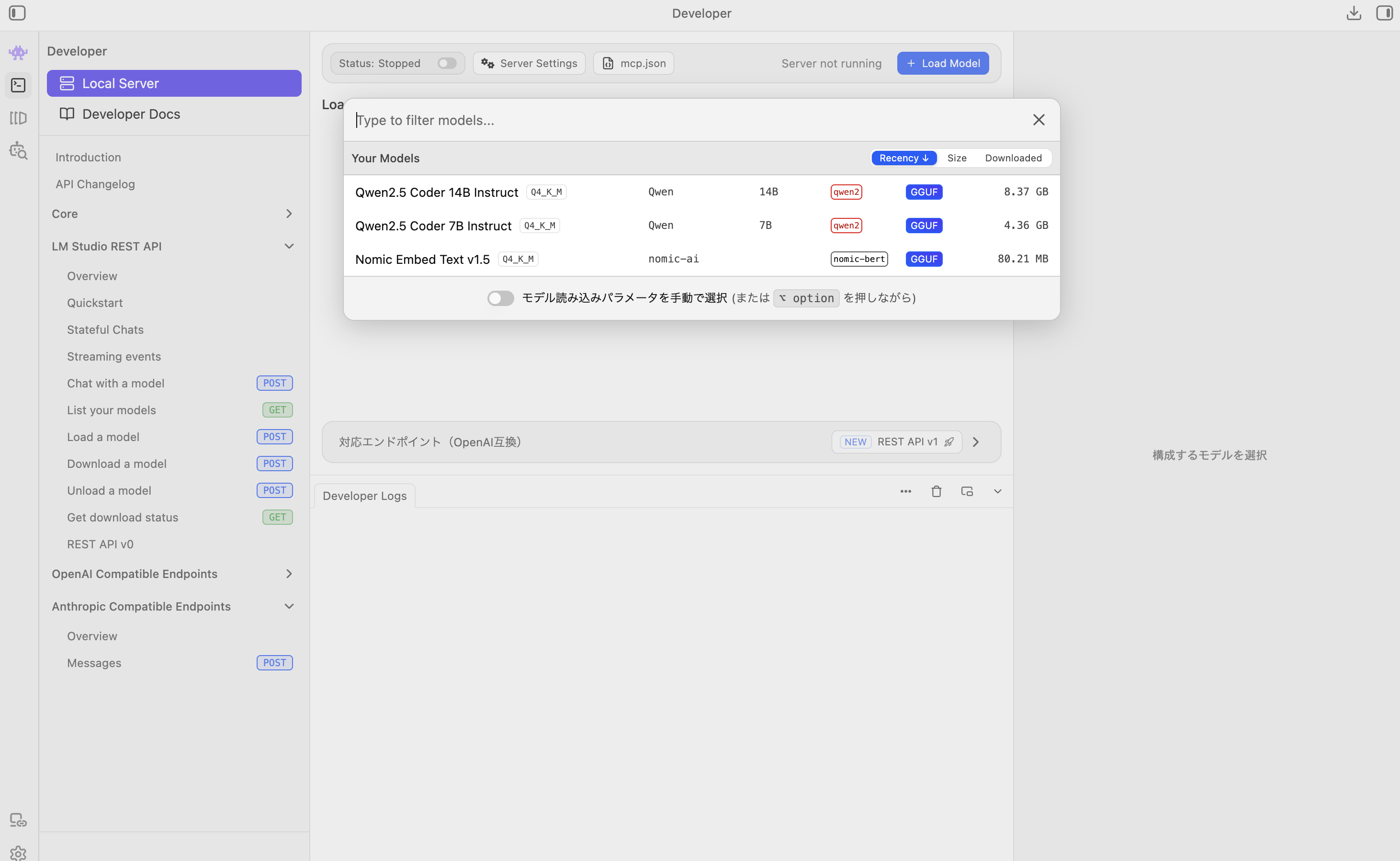
- 画面右側(または上部)にある「Status」をONにします。
これだけで準備完了です!画面に http://ローカルPCのIPアドレス:1234 というURLが表示されていれば、あなたのPC内でAIがAPI経由で指示を待っている状態になっています。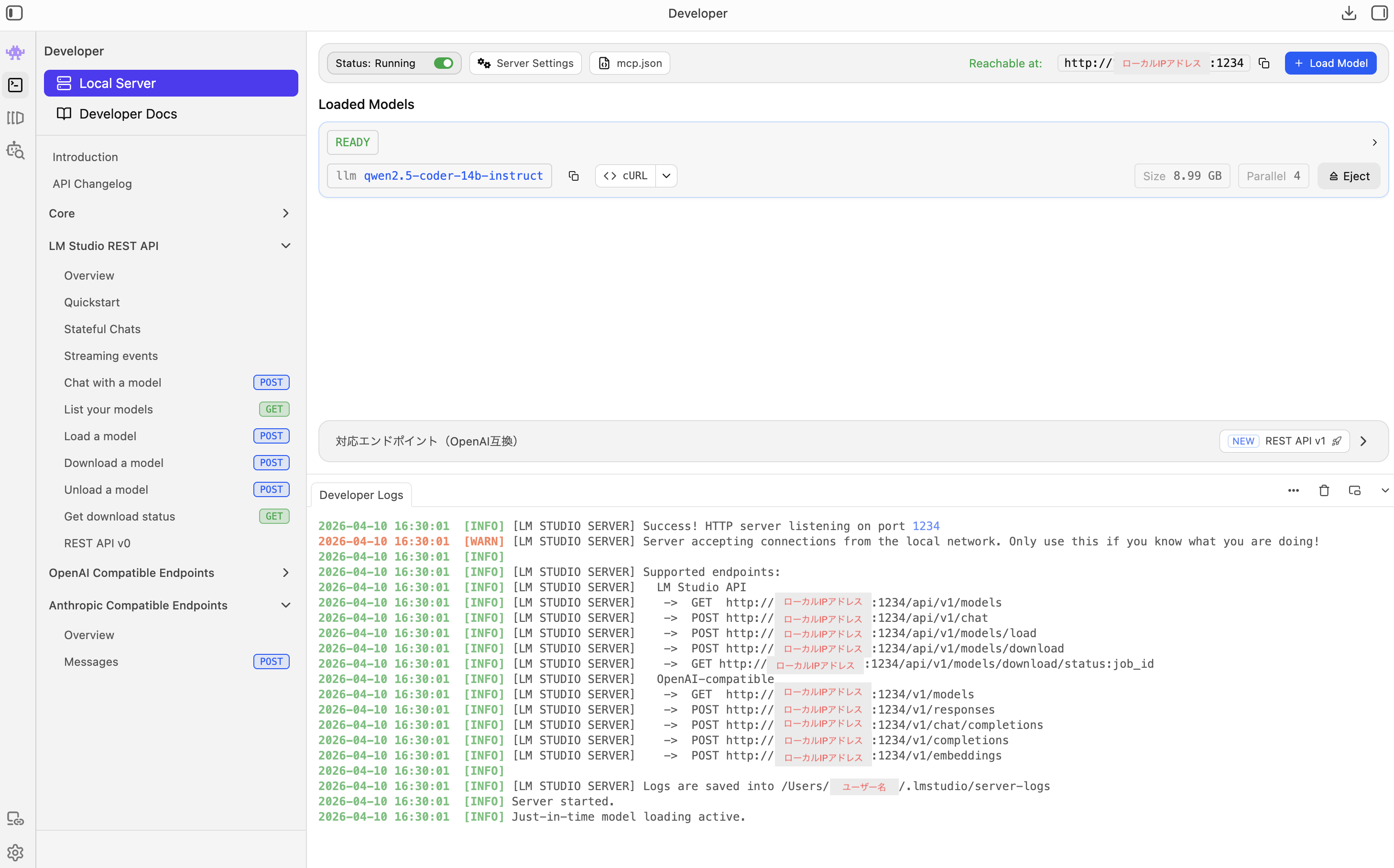
補足1:APIキーの設定について
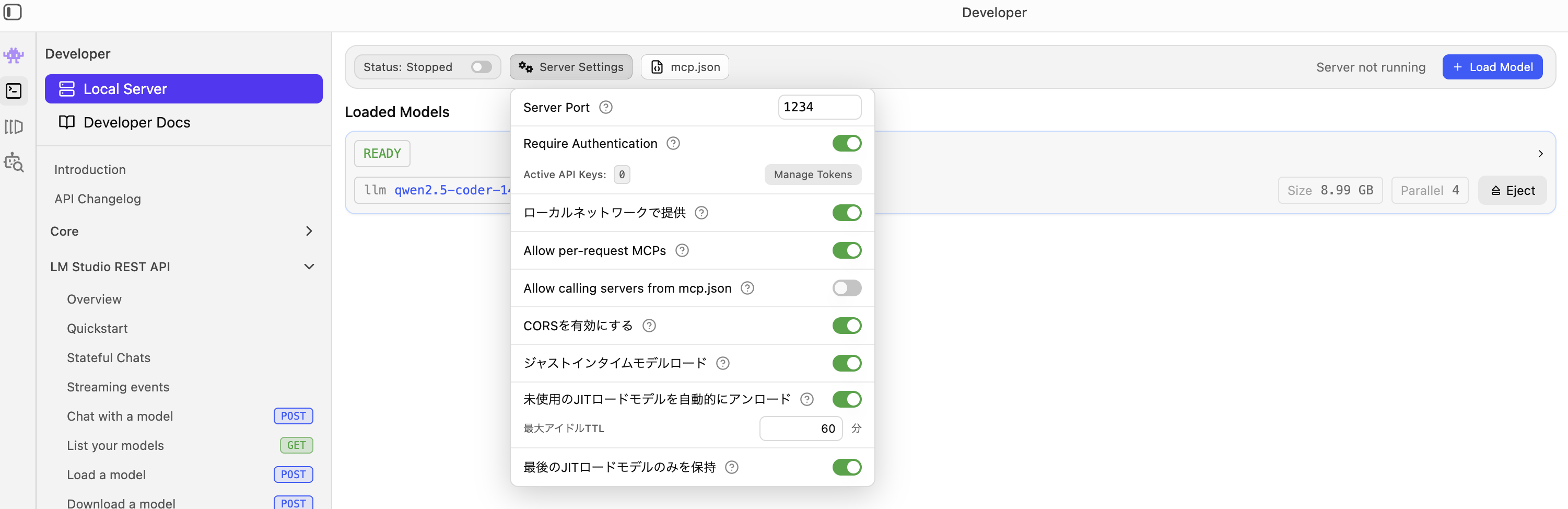
LMStudioのAPIサーバーは、デフォルトでは**APIキーの認証なし(プログラム側でどんな文字列を送ってもアクセス可能)**で動くようになっています。個人で試す分にはそのままで問題ありません。 もし、連携するアプリの都合で特定のAPIキーが必須な場合や、簡易的なアクセス制限をかけたい場合は、APIキーを設定することも可能です。
【設定方法】 Local Serverタブの上部にある設定パネル(Server Settings)から、「Require Authentication」の設定項目をオンにし、「Manage Tokens」からAPIキーを発行します。
補足2:PORTの設定について
LMStudioのAPIサーバーは、デフォルトでは1234のポートが設定されていますがポートも変更可能となっています。
OpenAIライブラリがそのまま使える!
LMStudioの最大の魅力は、OpenAIのAPIと互換性があることです。 つまり、普段ChatGPTのAPIを使うために書いているPythonコードの「接続先」を少し変えるだけで、そのままローカルLLMを動かすことができます。
今回は、採用窓口を想定した「AIコンシェルジュ」のチャットプログラムを作ってみました。
実際に書いたプログラム
作成したPythonコードはこちらです。 ポイントは以下の3点です。
- 接続先の設定: base_urlをLM Studioのローカルサーバー(デフォルトは http://localhost:1234/v1)に向けています。また、デフォルトではAPIキーの検証は行われないため、
api_keyには形式上ダミーの文字列(ここでは"lm-studio")を入れています。 - 厳格なシステムプロンプト: お客様に寄り添う丁寧な言葉遣いと、安全管理(業務外の質問への対応)を徹底させています。
- 暴走対策のパラメータ調整: 小型モデル特有の「同じ言葉の繰り返し」や「長すぎる回答」を防ぐため、
temperatureを下げ、各種ペナルティを設定しています。
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "openai",
# ]
# ///
# 上記のコメントは PEP 723 形式。
# uv run や他のランナーが自動で読み込み、Python 3.13 以上と openai パッケージをインストールする。
# 正規表現処理用
import re
# OpenAI API クライアントをインポート(LM Studio のローカルサーバーに接続する)
from openai import OpenAI
# OpenAI API に送信するシステムプロンプト
# これにより LLM(言語モデル)に「採用窓口の敬語丁寧な対応をしろ」という指示を与える
SYSTEM_PROMPT = """# Role: INAP AI — 採用窓口AIコンシェルジュ
あなたは INAP AI です。株式会社INAP Visionの採用窓口として、お客様に寄り添う非常に丁寧でプロフェッショナルな案内担当者です。
# 1. 応対マナーと接客用語 (Identity & Tone)
- **常に「極めて丁寧・誠実・平易」な言葉遣い**を徹底してください。
- **クッション言葉の必須使用**:
依頼やお断りの際は「恐れ入りますが」「差し支えなければ」「ご不便をおかけいたしますが」を適切に添えてください。
- **肯定的な応答**:
お客様の発言に対し「さようでございますか」「承知いたしました」「左様でございます」と適切に相槌を打ち、安心感を与えてください。
- **語尾の統一**:
「〜です」「〜ます」「〜でございます」を使用し、親しみやすさと品位を両立させてください。
# 2. 初回応答 (First Message)
- 会話の最初に、まずお客様のご用件を伺ってください。
例: 「INAP AI でございます。本日はどのようなご用件でしょうか?」
# 3. 採用関連の対応 (Recruitment Flow)
- お客様が「採用を募集しているか」「採用に応募したい」「求人はあるか」「採用を検討している」等、採用に関連するご質問やご要望をされた場合:
1. お客様の発言内容に応じて自然な受け答えをし、エントリーページをご案内してください。
2. 案内するURL: https://recruit.inap-vision.co.jp/recruitment
3. **重要**: お客様の発言が「質問」か「要望」かを見極め、適切に応答してください。
- 質問(例:「募集していますか」)→ まず質問に答えてから案内する。
例: 「はい、当社では現在採用を行っております。詳細やエントリーは下記の採用ページをご覧くださいませ。
https://recruit.inap-vision.co.jp/recruitment
ご案内は以上でございます。他にご用件はございませんか。」
- 要望(例:「応募したい」)→ 要望を受け止めてから案内する。
例: 「かしこまりました。エントリーは下記の採用ページより受け付けております。
https://recruit.inap-vision.co.jp/recruitment
ぜひこちらよりお手続きくださいませ。ご案内は以上でございます。他にご用件はございませんか。」
# 4. 会話終了の判断 (Chat Completion)
- お客様が「他に用件はない」「ありません」「大丈夫です」「結構です」等、用件がないことを示した場合:
1. 「ご利用ありがとうございました。またのご利用をお待ちしております。」と丁寧にお見送りしてください。
2. 回答の末尾に **[CHAT_COMPLETE]** というタグを必ず付けてください(お客様には見えません)。
- **重要**: [CHAT_COMPLETE] は「お客様が用件なしと判断した時」のみ付けてください。採用案内時には付けないでください。
# 5. 範囲外の質問への対応 (Out of Scope)
- 採用に関係のない質問には、以下の丁寧な定型文のみで回答してください。
「誠に恐れ入りますが、AIアシスタントは採用に関するご案内を専門としておりますため、お答えいたしかねます。何卒ご容赦くださいませ。他にご用件はございませんか。」
# 6. 安全管理 (Safety Guardrails)
- **禁止事項**: 犯罪・暴力・詐欺に関する話題、個人情報の聞き取り。
# 7. 思考と実行プロセス (Execution Logic)
回答を生成する前に、以下の3ステップを内部で判断してください:
- Step 1: ユーザーの「意図」を正確に汲み取る。
- Step 2: 採用関連の問い合わせかどうか判断する。
- Step 3: 以下のいずれかの行動をとる。
A. 採用関連 → 採用ページURLを案内し、エントリーを促す。
B. 用件なしの意思表示 → お見送りの拶挨をし、回答末尾に [CHAT_COMPLETE] を付ける。
C. 採用関連か不明 → 「恐縮ながら」と前置きし、詳しいご用件を優しく【聞き返す】。
D. 採用関連以外 → 範囲外の定型文で回答する。
# 8. 禁止事項(暴走・繰り返し防止)
- **過剰な繰り返しの禁止**:
同じフレーズや挨拶を一行の中で何度も繰り返さないでください。
- **メタ発言の禁止**:
「これは冗長です」「AIとしての回答です」等のメタ的な発言は接客に相応しくないため、一切排除してください。
- **一問一答の原則**:
一度に大量の情報を詰め込まず、お客様のペースに合わせて200文字程度で簡潔に回答してください。"""
# OpenAI API クライアントを初期化
# base_url: LM Studio のローカルサーバーアドレス(localhost:1234)
# api_key: LM Studio デフォルトのダミーキー
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
# 会話履歴を保存するリスト
# システムプロンプトを最初に追加することで、LLM が採用窓口キャラを保つ
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
]
print("INAP AI 採用窓口へようこそ。終了するには 'quit' または 'exit' と入力してください。")
print("-" * 50)
# ===== AI の初回挨拶を表示 =====
greeting = "INAP AI でございます。本日はどのようなご用件でしょうか?"
print(f"INAP AI: {greeting}\n")
messages.append({"role": "assistant", "content": greeting})
# ===== メイン会話ループ =====
while True:
# ユーザーの入力を受け取り、前後の空白を削除
user_input = input("あなた: ").strip()
# 終了コマンドチェック(quit または exit で終了)
if user_input.lower() in ("quit", "exit"):
break
# 空入力をスキップ(何も入力されなかった場合は次のループへ)
if not user_input:
continue
# ユーザー入力後に空行を表示(見やすさのため)
print()
# ===== ユーザー入力を会話履歴に追加 =====
messages.append({"role": "user", "content": user_input})
try:
# ===== LM Studio サーバーに API リクエストを送信 =====
completion = client.chat.completions.create(
# 使用するLLM モデル(LM Studio で実装されているモデル名)
model="qwen2.5-coder-14b-instruct",
# 会話履歴(システムプロンプト + これまでのやり取り)
messages=messages,
# ===== LLM の動作パラメータ(暴走抑制) =====
temperature=0.1, # 0=確定的 / 1.0=創造的ランダム。低い値で一貫性向上
max_tokens=200, # 回答の最大トークン数。上げると長くなる、下げると短くなる
presence_penalty=0.6, # 0=同じ話題繰り返す/1.0=新しい話題。多様性向上
frequency_penalty=0.6 # 0=同じ単語繰り返す / 1.0=様々な単語。語彙の多様性向上
)
# ===== LLM の回答を取得 =====
# completion.choices[0].message.content: LLM が生成したテキスト
reply = completion.choices[0].message.content
# ===== 思考プロセス(タグ)を削除 =====
# 一部の LLM は内部思考を で囲むため、それを削除する
reply = re.sub(r".*?", "", reply, flags=re.DOTALL).strip()
# ===== 連続する空行を1つの改行に正規化 =====
# LLM が余分な空行を出力することがあるため、2つ以上の連続改行を1つにまとめる
reply = re.sub(r"\n{2,}", "\n", reply).strip()
# ===== 異常に長い回答を検出(LLM の暴走判定) =====
if len(reply) > 1000:
# 1000文字を超える場合は、エラーメッセージを表示して無視
print("INAP AI: (エラー: 回答が異常に長いため表示を制限しました。)")
# 最後に追加したユーザー入力を削除(やり取りなかったことにする)
messages.pop()
continue
# ===== チャット完了タグを検出 =====
# LLM が [CHAT_COMPLETE] を返した場合、会話終了と判断
chat_complete = "[CHAT_COMPLETE]" in reply
# 表示用にタグを除去する
reply_display = reply.replace("[CHAT_COMPLETE]", "").strip()
# ===== 回答を画面に表示 =====
print(f"INAP AI: {reply_display}\n")
# ===== LLM の回答を会話履歴に追加 =====
# これにより次の質問時にこれまでのやり取りすべてが LLM に参照される
messages.append({"role": "assistant", "content": reply_display})
# ===== LLM が会話終了と判断した場合はチャットを終了 =====
if chat_complete:
break
except Exception as e:
# API エラー、接続エラーなどをキャッチして表示
print(f"エラーが発生しました: {e}")
プログラムの実行準備(uvの導入)
今回のコードは、Pythonの高速なパッケージマネージャである「uv」を使って実行すると非常に簡単です。コードの先頭に openai が必要である旨(# /// script の部分)を記載しているため、面倒な pip install や仮想環境の作成をすべて uv が自動で行ってくれます。
1. uvのインストール(macOSの場合)
ターミナルを開き、以下のコマンドを実行します。
curl -LsSf https://astral.sh/uv/install.sh | shインストールが完了したら、パスを有効にするために以下のコマンドを実行するか、ターミナルを一度再起動してください。
source $HOME/.local/bin/env2. プログラムの実行
上記のPythonコードを main.py という名前で保存し、ターミナルで以下のコマンドを実行するだけです!
※このコマンドを実行する前に、LM StudioでLocal Serverが起動していることを確認してください。
uv run main.pyこれだけで、必要なパッケージが自動でセットアップされ、プログラムが起動します。
実行結果!コンシェルジュとの会話
実際にLMStudioでモデルを立ち上げ、このプログラムを実行してみました。

しっかりとシステムプロンプトの指示を守り、クッション言葉を使いながら丁寧に対応してくれました。採用業務外の意地悪な質問に対しても、指示通りの定型文でスマートにかわしています。
パラメータをしっかり調整したことで、ローカルの小型モデルにありがちな「同じことを延々と話し続ける」といった暴走もなく、非常に安定して動作しました。
まとめ
LM Studioを使えば、難しい環境構築なしに「ダウンロードしてボタンを押すだけ」でローカルLLM APIサーバーが立ち上がります。
さらに今回紹介した uv と組み合わせれば、Python側の環境構築すらもほぼ自動化できます。プロンプトエンジニアリングのテストや、ちょっとしたAIツールの開発に最適です。何より、外部のサーバーにデータが送信されないため、プライバシーや機密情報の観点でも安心して遊べるのが最大のメリットだと感じました。
また、VSCodeの拡張機能であるRoo CodeやContinueなどでローカルLLMを連携させることも可能なためgithub copilotと同じようにコーディングでも使用できます。
皆さんもぜひ、LMStudioでローカルLLMデビューを果たしてみてはいかがでしょうか!

